
Changelog LTS Version Q2 26
Improvements such as enterprise-grade team management, expansion of the Managed Services ecosystem and new runtimes (managed virtual Kubernetes cluster and a managed container)
Search all our Docs and Blog to find what you're looking for.
Improvements such as enterprise-grade team management, expansion of the Managed Services ecosystem and new runtimes (managed virtual Kubernetes cluster and a managed container)

What's new: Managed Services for Postgres and S3, landscapes to be published as service providers, redesigned Execution Manager, custom Docker image support, virtual Kubernetes workloads, and enhanced accessibility features

It's the buzzword of the moment: sovereignty. Everyone is talking about it. But we still confuse data centre addresses with control. Here's why Deutschland-Stack, open architectures and a genuine sovereignty layer make all the difference, and what we should be doing in practical terms right now.

What's new: A fully revamped IDE, a new managed PostgreSQL service, and major improvements to platform observability and accessibility.

Discover hidden Codesphere features that can transform your development workflow. From advanced deployment tricks to productivity shortcuts, unlock tools you never knew existed.
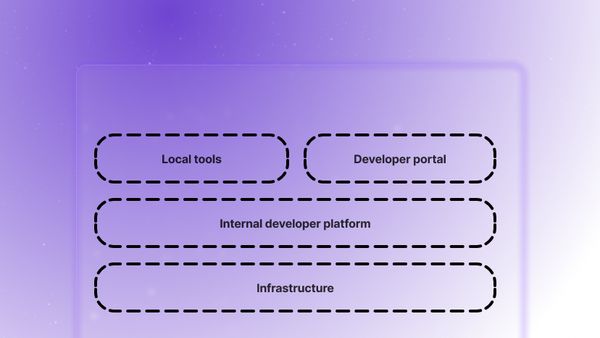
Decoding the modern developer experience. Learn the key dimensions to evaluate them and discover what lies beyond the traditional IDP model.

New cli, restricted domains, improved git integration, frontend improvements and more in the latest LTS version.

Tired of the “It works on my machine” nightmare? This blog explores how Codesphere eliminates environment drift by letting you develop in production-grade cloud workspaces. so your code runs the same everywhere, from dev to deploy. Build smarter, ship with confidence.

Discover how Codesphere transforms software development by unifying coding, CI/CD, deployment, and infrastructure into one seamless platform. Boost developer productivity, reduce DevOps overhead, and go from idea to live without switching tools or breaking flow.

On June 14 & 15 more than 80 engineers filled our Karlsruhe office with an unforgettable energy.

Discover how to run Ollama with Open WebUI using a streamlined Codesphere deployment. This blog walks through the benefits, use cases, and a complete step-by-step setup to launch a private, local LLM environment
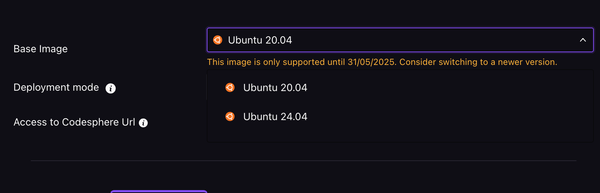
As part of our ongoing commitment to security and stability, we want to inform you that the Ubuntu version used in workspaces created prior to May 21 2025 is approaching its end of life.