Deploying Faster-Whisper on CPU
Learn how to deploy a faster whisper server to increase transcriptions speeds by 4x and enabling real-time voice transcription on CPU only hardware.
Table of Contents
Whisper is the open source voice transcription model published by OpenAI. And it is pretty impressive on its own already delivering accurate voice transcriptions in 30+ languages. Working with it locally is also quite convenient and the performance on most laptops will be okay.
However for one the use cases we were building it was not quite fast enough for a real-time voice transcription on the available on-premise hardware. We started looking into the available options for accelerating its performance. That is the amazing thing about open-source projects like this one, usually you don't have look far or start from scratch someone else has already done (most) of the work and you can pick up with quite a head-start.
The repository we are checking out today is https://github.com/fedirz/faster-whisper-server which is a webserver using the faster-whisper backend which uses CTranslate2 to speed up inference by up to 4x.
Let's use this blog post as an example of a more generally applicable process of how to take a Docker distributed open source project and cut out Docker as heavy and inefficient middle man.
- Let's clone the repository (I'm doing it directly on a Codesphere CPU workspace but locally works just as well)
- Let's dissect the dockerfile:
FROM ubuntu:22.04
# `ffmpeg` is installed because without it `gradio` won't work with mp3(possible others as well) files
# hadolint ignore=DL3008,DL3015,DL4006
RUN apt-get update && \
apt-get install -y ffmpeg software-properties-common && \
add-apt-repository ppa:deadsnakes/ppa && \
DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends python3.12 python3.12-distutils && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
WORKDIR /root/faster-whisper-server
COPY requirements.txt .
RUN --mount=from=ghcr.io/astral-sh/uv:latest,source=/uv,target=/bin/uv \
uv pip install --system --python 3.12 --no-cache -r requirements.txt
COPY ./faster_whisper_server ./faster_whisper_server
ENV WHISPER__MODEL=Systran/faster-whisper-medium.en
ENV WHISPER__INFERENCE_DEVICE=cpu
ENV WHISPER__COMPUTE_TYPE=int8
ENV UVICORN_HOST=0.0.0.0
ENV UVICORN_PORT=8000
CMD ["uvicorn", "faster_whisper_server.main:app"]From this we can learn all we need to in order to set up our environment. Firstly we need a Linux environment (already there), secondly we need ffmpeg (I just use https://search.nixos.org/packages to search for a lightweight ffmpeg and install it via Nix nix-env -iA nixpkgs.ffmpeg_7-headless).
Other than that we need python 3.12 and a bunch of environment variables. Python 3.12 was actually the only semi tricky thing here and only because we need to update the pre-installed Pyenv version in Codesphere to cover the latest Python versions (added it to our backlog).
Workaround for Python 3.12 for now:
Set PYENV_ROOT to /home/user/app/.pyenv in env vars and create a new terminal. Then execute the following:
cd ..
rm -rf .pyenv
curl https://pyenv.run | bash
cd app
pyenv install 3.12.4
PIPENV_YES=1 pipenv install --python 3.12.4- Now we install the dependencies via
cd faster-whisper-server && pipenv install -r requirements.txt - And then start the application with
WHISPER__INFERENCE_DEVICE=cpu WHISPER__COMPUTE_TYPE=int8 UVICORN_HOST=0.0.0.0 UVICORN_PORT=3000 pipenv run uvicorn faster_whisper_server.main:appNow we have our faster-whisper server running and can access the frontend gradio UI via the workspace URL on Codesphere or localhost:3000 locally. Time to give it a test, to see how the performance actually stacks up. I'm using a 2:56 minute long sample from a podcast with the faster-whisper-medium model and a Codesphere CPU Pro plan (8vCPU & 16GB RAM) and I can transcribe the ~3 minutes in roughly 60 seconds - which is fast enough for real-time transcription scenarios like the one we needed in this case.
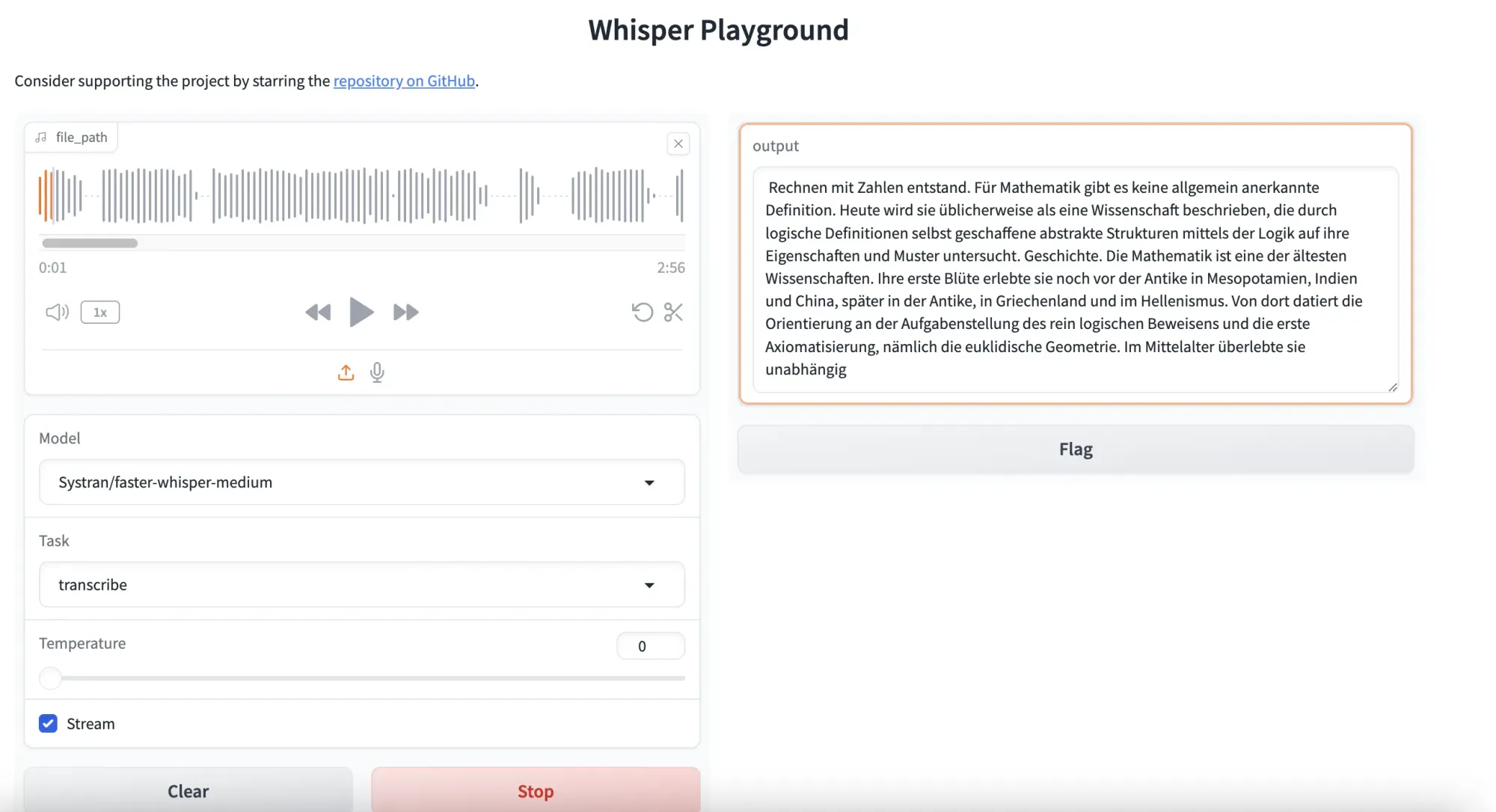
Plugging this into our existing frontend is also super convenient because the API follows OpenAIs specification so it's basically a drop-in replacement.
It does also offer a real-time transcription via websocket connection but for the purpose of this blog post I was not able to get this working properly
