Extracting Metadata from PDFs with Named Entity Recognition using Spacy
NER identifies entities like people and locations in text. SpaCy automates this with pre-trained models, offering accuracy, speed, and multi-language support. It excels at handling large datasets efficiently compared to rule-based methods.

Named Entity Recognition (NER) is a crucial component of Natural Language Processing (NLP) that focuses on identifying and classifying key elements within text into predefined categories. These entities typically include names of people, organizations, locations, dates, monetary values, and more. NER also assists in the organization of such unstructured information thus enhancing the retrieval of useful information.
Imagine a tool that processes enormous volumes of text in seconds with pinpoint accuracy, identifying those names, places, and organizations and integrating very smoothly into the workflow—without the need to write even one complex rule. All of that is possible in the world of spaCy. From legal documents, scientific papers or huge datasets, this natural language processing solution with the ability and speed to extract meaning from your data is unbeatable.
How NER Works?
Here is an overview of how NER works:
1) Text Input: The process begins with a block of unstructured text.
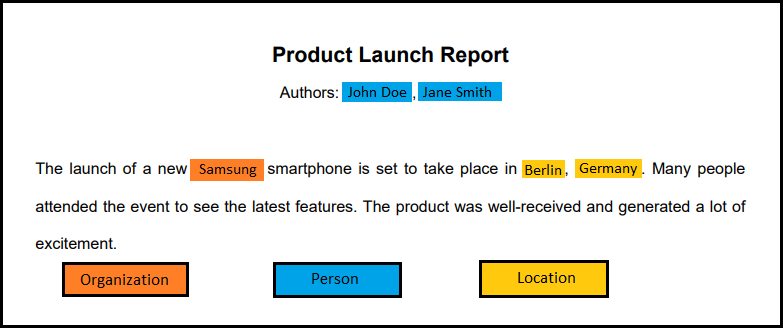
For example:
"Product Launch Report
Authors: John Doe, Jane Smith
The launch of a new Samsung smartphone is set to take place in Berlin, Germany."2) Tokenization: The text is divided into smaller units called tokens (words, phrases).
For instance, the above text would be tokenized into:
tokens = [ "Product", "Launch", "Report", "Authors", ":", "John", "Doe", ",", "Jane", "Smith", "The", "launch", "of", "a", "new", "Samsung", "smartphone", "is", "set", "to", "take", "place", "in", "Berlin", ",", "Germany", "." ] 3) Entity Detection: The system identifies contiguous spans of tokens that represent named entities. This step can be done using:
- Rule-Based Systems: Predefined patterns and grammar rules are used to identify entities.
- Statistical Models: Machine learning algorithms (like Conditional Random Fields) are trained on annotated datasets to recognize entities based on context and features.
4) Entity Classification: Each detected entity is classified into categories. For example:
"John Doe, Jane Smith" → Person
"Samsung" → Organization
"Berlin, Germany" → Location
5) Generation: The processed text is outputted with the entities highlighted and classified. For example:
"Product Launch Report
Authors: [John Doe, Jane Smith]
The launch of a new [Samsung] is set to take place in [Berlin, Germany]."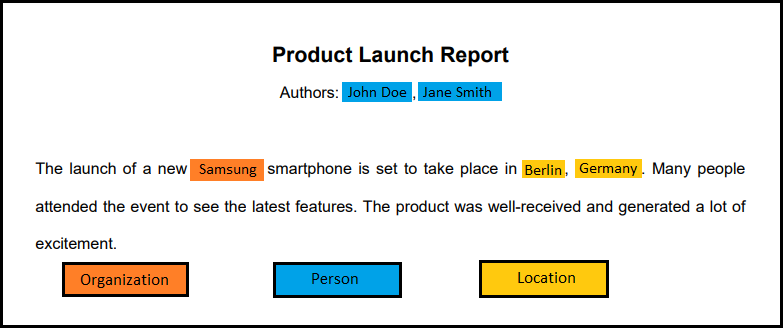
Overview of spaCy:
The Spacy frameworks are a top choice for Named Entity Recognition (NER). It has many features that meet different needs. Its user-friendly API makes it easy to use in various NLP workflows. This means developers and data scientists can use it without needing a lot of training.
The Spacy frameworks are great for handling many NER tasks. It's very accurate and fast. It comes with pre-trained models that can spot many types of entities, like people, companies, and places. This is super helpful when working with texts in different languages, as Spacy works with many languages. Its standout features include:
- Support for 75+ languages
- 84 trained pipelines for 25 languages
- Multi-task learning with pretrained transformers
- Support for custom models, Integrates seamlessly with frameworks like PyTorch and TensorFlow etc.
- Built-in visualizers for syntax and NER
Why spaCy Stands Out?
When comparing spaCy with the rule based methods for carrying out a natural language processing task it is unarguable that spaCy scores best. The traditional approaches over-depend on rules that are often formulated such as word patterns, lists of keywords and stop word filtration which entails a lot of work and time and in most instances mistakes are common. While these techniques may seem ok with the limited data. More maintenance and customization is needed when more data comes into the picture. However, spaCy applies advanced methods of machine learning and pattern recognition models to recognize and classify nouns in text. Developers can now do it without wasting extensive time on refining rules because spaCys strong framework reduces the human errors commonly seen in rule based systems.
Comparison: Regex vs. spaCy
In our findings, we compared the performance of a regex pattern used to identify first and last names based on two consecutive words with initial capital letters against spaCy's named entity recognition (NER). The regex pattern we used is:
\b[A-Z][a-z]+\s[A-Z][a-z]+\bThis pattern did match phrases such as "Maria Garcia" or "John Muller," effectively catching first and last names. But it mistakenly identified non-name phrases such as "Risk Report" or "Page One," which caused errors in the extraction process.
On the other hand, spaCy's NER performed far better when it came to recovering names and removal of irrelevant capitalized terms . When the same text was being processed using spaCy, it correctly identified "Maria Garcia" and "John Muller," while ignoring phrases that won't stand for individuals. This example demonstrates how spaCy manages named entity extraction in much more precision with more contextual knowledge compared to regex patterns. One known limitation that we also encountered is that since Spacy models are language specific it might struggle to recognize non-English names, especially those with non-English characters in them.
The following table summarizes the key differences between traditional rule-based methods and spaCy:
How to Integrate spaCy?
Integrating spaCy into your project is straightforward, making it an ideal choice for enhancing your natural language processing capabilities. Here’s a step-by-step guide to getting started:
- Installation:
Install spaCy via pip by running the command:
pip install spacy- Download a Language Model:
Choose and download a pre-trained language model that suits your needs. For example, for English:
python -m spacy download en_core_news_sm- Import spaCy in Your Project:
Add the following import statement at the beginning of your Python script:
import spacy - Load the Language Model:
Load the downloaded model into your script:
nlp = spacy.load("en_core_news_sm")- Process Text:
Use the nlp object to process your text and extract information:
doc = nlp("Here is a sample text.")
for ent in doc.ents:
print(ent.text, ent.label_)- Run spaCy in Air-Gapped Environments
If you need to run spaCy in an air-gapped environment (where internet access is restricted), follow these steps:
- Download the Model on a Machine with Internet Access:
Use a machine that has internet access to download the desired language model. For example, to download the English model, use the following command:
python -m spacy download en_core_web_sm --direct- Transfer the Model Files:
i. Locate the downloaded model tar file in the directory.
ii. Copy the entire model directory to a USB drive or other storage device.
iii. Transfer the directory to your air-gapped environment.
- Load the Model in Your Air-Gapped Environment:
In your air-gapped Python environment, place the model directory in a known location (e.g., /path/to/spacy_models/en_core_news_sm) and unzip it.
Load the model using the local path with the following code:
import spacy
# Load the model from the specified local path
nlp = spacy.load("/path/to/spacy_models/en_core_web_sm)- Integrate with Other Libraries:
spaCy can easily work alongside other libraries such as Pandas, TensorFlow, or PyTorch. For instance, you can convert spaCy documents into a format compatible with machine learning frameworks.
Example Implementation of Author Extraction Using spaCy
The following code snippet loads a pre-trained English language model and applies Named Entity Recognition (NER) to extract names from a given text. This example showcases how spaCy simplifies the process of identifying authors in text.
# Example implementation of author extraction using spaCy
import spacy
from typing import List
def load_model() -> spacy.Language:
#Load the pre-trained spaCy model
return spacy.load("en_core_web_sm")
def apply_ner(nlp: spacy.Language, text: str) -> List[str]:
#Extract PERSON entities (names) from text.
names = []
doc = nlp(text)
names = [ent.text for ent in doc.ents if ent.label_ == "PERSON"]
return names
def extract_authors(text: str) -> List[str]:
#Main function to extract authors from the given text.
nlp = load_model()
names = apply_ner(nlp, text)
return names
# Example usage
if __name__ == "__main__":
sample_text = """
Risk Report as of 31.03.2023
I. Proposal for Decision:
The results were falsified to avoid disclosing data. The board acknowledges the risk report.
Several experts were involved in the preparation of this report. John Doe and Jane Smith were significantly involved in the analysis of the risk factors. Lisa Pitt also made valuable contributions, especially regarding the latest market developments.
In summary, this report provides important insights into the company's risk factors and contributes to improved decision-making. The mentioned individuals are available for further inquiries.
"""
authors = extract_authors(sample_text)
print(f"Extracted authors: {authors}")
Conclusion
In conclusion, spaCy is a robust and widely applicable NLP library aimed at efficiently dealing with large datasets, speed, and accuracy. Therefore, due to its integration capabilities and the support that it provides in multiple languages, spaCy is found suitable in healthcare and finance. SpaCy played a significant role in accelerating valuable insights from using advanced techniques of machine learning so that the user can devote all their energy towards analyzing solutions rather than manually creating rules. With organizations increasingly adopting NLP, spaCy is yet another great weapon to consciously analyze and extract text data in their benefits.
