Taking Advantage of the Long Context of Llama 3.1
Llama 3.1 allows a context window of 128k tokens. We investigate how to take advantage of this long context of Llama without running into performance issues.


The evolution of large language models has significantly improved their capacity to process and generate text. One of the more crucial developments in this regard is the extension of context length or context window for these LLMs. From the best models on the market offering just 1k Tokens to now the limit being 200k for some of the latest models. Lama 3.1 is one of the models that is at the forefront of this trend, it has a context window of up to 128k tokens. This can open up new possibilities for handling extensive documents, improving long conversations and accurately performing complex data-retrieval tasks. However, with bigger context windows comes the question of higher computational costs. So I wanted to investigate how well you can take advantage of the long context of Lama 3.1 and that is what we will do in this article. However, I would like to start by explaining what context length is and why it is important.
What is Context Length?
Context length commonly known as context window is the maximum number of tokens that a language model can process at one time. In simpler terms, it's the “memory” of the model during a single interaction. The older versions of Llama had relatively limited context length typically up to 32 k, Llama 3.1 pushes this to 128k which can open up many possibilities. While a bigger context window is generally great this can introduce significant accuracy problems towards the upper bounds. The question we are seeking answers to today is if the model performance decreases dramatically as the context window increases. It would be great to discuss at this point how context length plays a role in performance.
What is the Role Of Context Length in LLM Performance?
The importance of context length lies in its direct impact on the performance and usability of a language model. A longer context length allows for:
Improved Coherence: With a larger context, the model can better understand and generate text that is consistent with the earlier parts of the input. For example, if you are having a chat with an LLM it would be able to remember a larger chunk of your chat if the context window is bigger. This is particularly important in use cases where maintaining continuity over long passages or chats is critical.
Enhanced Information Retrieval: When dealing with large datasets or documents, a model with an extended context window can reference more data at once, potentially retrieving and synthesizing information more accurately. This reduces the need for segmenting documents or breaking down queries into smaller parts.
Complex Task Handling: Long context LLMs can in theory handle more complex tasks that require understanding relationships between widely separated pieces of text, such as multi-turn conversations or cross-referencing information from different parts of a document.
How to Use Context Length?
When you're working with a model like LLaMA 3.1, which has a huge context window, it's smart to be strategic about how you feed it information. There are two very useful strategies you can utilize to help LLM process text better.
- When working with really long documents within the context window of the model itself, it's a good idea to break them down into smaller sections and add summaries. This helps the model stay on track and process the text better.
- You should also try to place the most important information at the start and end of your input because studies have shown that models often exhibit a "U-shaped" performance curve. So models like LlaMA often remember the start and end parts of a document better than what's in the middle.
Our Experience With Llama 3.1
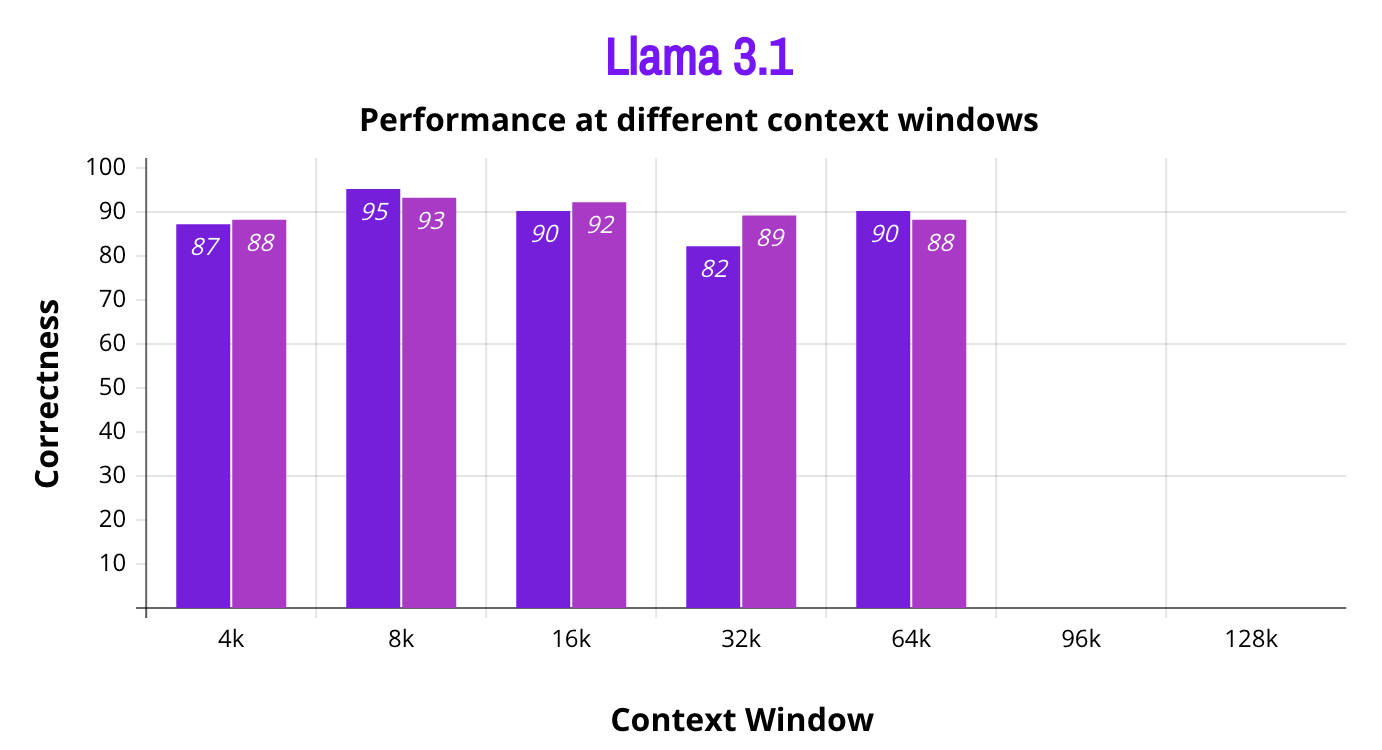
We decided to check the accuracy of Llama 3.1 at different context lengths to assess how the performance varies at different context windows. As Llama 3.1 is trained on publically available data, we asked chat GPT to generate 2 sets of 100 random questions each, to test the text generation accuracy at different context windows. To make sure the outcomes were consistent, the test for repeated twice at every context window for each set of questions. The parameters for Llama cpp were set as following:
Predictions: 400, Temperature: 0.7, Penalize repeat sequence: 1.18, Consider N tokens for penalize: 256, Top-k sampling: 40, Top-P sampling: 40, Penalize repetition of new lines: unchecked, Min-P sampling: 0.05 Penalize repeat sequence
The correctness of the answers to these questions was evaluated by using GPT-4o as a judge, AI’s judgment of the correctness is at par with the human judgment or evaluation of the same questions. We gave the same set of questions to the Llama 3.1 8B model by setting the context window at 8k, 16k, 32k, 64k, and 96k respectively. The results were interesting, the model exhibited the highest accuracy at 8k, and at 16k the performance slowly deteriorated as the number increased but not significantly. However, at 96k it got painfully slow where it started answering one question a minute while using 8 vCPUs with 16 GB RAM. Most of the questions these models at different context lengths got wrong were the same and not so surprisingly the wrong answers they gave were the same. For example, at every context length the model answered the question “Who was the first person to reach the South Pole?” as Robert Falcon Scott which is incorrect, the correct answer was Roald Amundsen.
Will Long Context LLMs Subsume RAG?
Retrieval-augmented generation (RAG) is a method that helps language models be more efficient by combining the strengths of retrieval systems with the generative capability of LLMs. When a user makes a query, RAG first looks for the most relevant information from a large database or corpus. This information is then used as input for the LLM to generate an accurate and contextually relevant answer. Unlike simply feeding the LLM with everything at once, RAG picks out the most important pieces of information thus leading to better and faster results.
The rise of massive context windows in language models, capable of handling over a million tokens, has sparked discussions about potentially replacing RAG. However, while large context windows enable more extensive use cases, they do not signal the end of RAG. Bigger context windows that seem to give the best results for now will allow RAG to retrieve more information, which will further improve the quality and relevance of answers generated by LLMs. This suggests large context windows and RAG are complementary rather than mutually exclusive.
Although large context windows enhance processing capabilities, they come with significant computational costs and latency. This could be changed in the future to some extent but for now, RAG is more reliable and cost-efficient. In addition to that RAG currently has better scalability, improved performance across diverse data sources, and the ability to handle complex tasks efficiently. This means despite advancements in context window size, RAG remains essential, particularly when dealing with large-scale information processing in a cost-effective manner.
Conclusion
The new increased context window limit for Llama 3.1 works great with a RAG, providing better context and understanding. However, it does not work as efficiently as you start getting to the upper limit of the context window. The performance slightly decreases and it starts giving out false answers which are mostly caused by misunderstandings of the context, incorrect factual information, or overcomplication of the answer. One example of incorrect factual information can be the answer given by models as CO2 to the question “What is the most abundant gas in Earth's atmosphere? “. The right answer is Nitrogen. Going towards the upper limits of the allowed context window also decreases the speed so much that it is no longer computationally viable or sustainable.
However, there remains a question still unanswered: whether the performance of an LLM differs within a set context window i.e. after setting the limit to say 8k and then avoiding the last 2k tokens for improved accuracy. We would love to hear your thoughts or experiences about it.
